What CMS are you using?
What WordPress plugin do I use to make a clock like yours?
You're using AppEngine right? I can tell by your blog's IP address.
Brandon, when are you going to nerd out and talk about technical stuff?
Right now, as it turns out. First, a little disclaimer:
This post is more for the technical types. You'll likely find this post mind-numbingly boring if you don't have an interest in programming or web development.
Still reading? Sweet. While I can't talk about what I work on in my day to day professional life, I can talk about my background and blog-related things, which in my opinion are more interesting. If you want juicy technical details, skip the "Background" section, that's just me reminiscing over a time in my life where I didn't have to come to grips with being an adult and stuff.
Background
On the sidebar, I mention that I'm a "Software Engineer". I capitalize Software and Engineer because it's my Official Title™ and it makes me feel Very Important™. I didn't always hold this position though, so let's start at the beginning.
For some reason unbeknownst to my current-self, a smaller, younger version of me had it in his silly little head that he wanted to be a lawyer. Maybe it was the allure of bucket-loads of bucks and the promise of putting particularly unpleasant people in prison, I can't say for sure. In any case, I shot down that dream while filling out a health form (or something similar) and realizing that I hated paperwork. Considering being a lawyer is like 99% paperwork (with the other 1% being bureaucracy and more paperwork), I opted for a far less miserable dream.
My first formal introduction to programming was at nerd camp when I was 13. I learned the fundamentals of C, building a basic command-line choose-your-own-adventure game. That was cool and all, but it was actually one of the other classes that caught my attention. A different course was using Multimedia Fusion, a programming platform with an easy click-and-drag UI. When you're 13 years old and you just made your first text-based game, that feels pretty sweet. When you look over and the kid next to you has made a full-on graphical game complete with sprites and sounds, you know it's time to step up your game.
So after camp was all over and done with, I started experimenting with this Multimedia Fusion software. I eventually got good enough with it to actually work with Clickteam, the company producing the software, and I built some educational children's games to showcase their tools. Multimedia Fusion was really a gateway programming language though, and it wasn't long before I started looking elsewhere to get my fix.
I spent five summers in my hometown as a parking lot attendant, and as the beach/lot became more popular over the years, people started asking for a way to make parking reservations online. Being the enterprising 17 year-old that I like to think I was, I whipped up a web app in PHP (for no other reason than I didn't know any better), and an accompanying Android app. This PHP app was hands-down the worst thing I'd ever written in my life. Not only did it have zero testing/version control/productionization/comments/coherence/style of any kind, the codebase was essentially a Franken-program of half-working snippets from Stack Overflow duct-taped to a MySQL instance hosted on a now-defunct web host, with all the worst CSS attributes in existence plastered onto the frontend. Somehow it worked though, and every day I'd use the Android app to keep a live-updating count of how many cars were in the lot, and people would pay me a dollar a piece to reserve a spot.
In college, I did a little bit of everything. I drove buses, programmed bus websites, graded for classes, and picked up contracts for any project I could get my hands on. Along the way I dabbled in Ruby/Rails, Python, Node.js, some Android stuff, a ragtag collection of web frameworks/technologies, and even a bit of assembly. I eventually stumbled upon Golang, and that's what most of the code I write of my own volition ends up being in, including this blog.
The Blog
At a high-level: this blog is written in Golang and hosted on Google App Engine. Posts and questions are stored in Datastore, and images are stored in Blobstore. The frontend is your standard HTML/CSS/Javascript stack with a sprinkling of Bootstrap because, let's be honest, nobody actually enjoys frontend web dev. I don't use Markdown or any other markup languages; posts are written in plain ole HTML, with the odd CSS class added to my stylesheet for new functionality.
Golang
If you haven't heard of Golang before, allow me to make the introduction. It's a fairly simple language, looks like a bastard child of C and Pascal, and puts primitives for concurrency right into the language. It's compiled and garbage-collected, which means deployments come in the form of single solitary binaries, and memory leaks are less likely to exist/ruin your day. If you're familiar with C or Java, you can probably learn the language in an afternoon. Built right into the standard library is a world-class HTTP package, as well as a templating system, and there's an extensive network of tooling covering everything from linting and formatting to deadlock detection and code coverage.
App Engine
App Engine is the magical piece of technology I use to host my code. It's kind of like Heroku, if Heroku didn't hold your hand quite so tightly and was built on big-boy infrastructure. It provides a great local development environment for me to iterate on, and deployments take <30 seconds. The built-in logging, monitoring, profiling, load-balancing, versioning, and auto-scaling, among a dozen other features, mean that I can focus on the blog and not unrelated productionization details.
Savings Clock
The code for the savings clock can be found at the bottom of this Javascript file. It's basically just a function that runs once a second and calculates my savings given some hard-coded values and the current date/time. Since my insurance rate is variable (as is the cost of rent), I divide the time between May and whenever into "epochs", each of which has a start and an end date, and the insurance and rent prices for those respective time periods. Then I iterate over the epochs, noting whether or not we're in the middle of one, and sum up the savings over all of them. Before updating the display on the page, I check if the value is negative (which it isn't anymore!) and format it appropriately.
Optimizations
I threw the blog together over the course of a few days in May, back when I was still unsure whether or not I could actually live out of a truck. Being the hectic time that it was, my main concern wasn't code quality or adequate testing coverage, but rather getting my thoughts onto the proverbial paper while they were still fresh in my mushy, unreliable mind. This was fine for a while, but I couldn't help but notice that each new feature took longer to integrate, and was more frequently broken than not. I knew it was time for an overhaul.
The Refactoring
The scenario is familiar to anyone who's ever done a bad job at maintaining a codebase: editing existing code becomes painful, and adding new features becomes brittle and burdensome, normally involving lots of copy and pasting and manual testing. In my case in particular, there was little to no isolation between components, and I was passing around global objects like it was nobody's business. So I started a new branch (because I use git and Github like a reasonable human being), and set to work. The first big change I made was wrapping App Engine's Context with my own and passing that into all my request handlers. Then I added interfaces for database lookups to decouple the implementation details from the business logic. Wrapping the default templating system with my own helped to get rid of the code duplication surrounding rendering common components, and a bunch of other small code clean up tasks around the site reduced complexity and fragility. Abstracting things like pagination and post creation out into their own independent ideas further slimmed the handler methods. Since everything is easier to test with proper abstraction, I tossed in a few more unit tests for basic functionality, and finished up by running the golint and go vet tools and implementing the suggestions they provided. A few weeks and a few thousand lines of code later, we're here, with a much more maintainable web app. To celebrate, I started adding a few new features.
Caching
When this blog was only getting 10 hits a day, it didn't matter how inefficiently I served up my content. After all, Datastore read/write requests are charged by the millions. I could have ran the website on a Raspberry Pi and nobody would have been any the wiser. But my fleeting collision with the limelight meant that suddenly those redundant calls started to add up. It wasn't until recently I realized something that should have been abundantly obvious from the outset: I'm the only one who updates the content on the site, I don't need to check the database to see if it's been updated. I can store pretty much everything in memory and serve from there, refreshing the in-memory representations anytime I create or edit a post.
Uh Brandon, you know that there's Memcached for that sort of thing, right? In fact, it's even integrated into App Engine.
I…I actually didn't know that. And if I had known that earlier, I probably would have done that. But since I had just finished my refactoring, it was a snap to add in a caching interface, and then drop the business logic into my new Context before it delegated calls to the Datastore.
Parallelism
A couple days ago, I stumbled upon the Cloud Trace feature of App Engine. So I turned it on, loaded the main page, and saw the following:
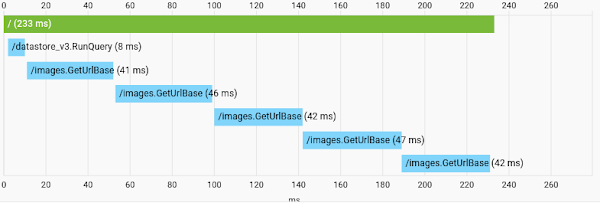
Well that's no good.
Can you spot the cardinal sin? I'm using a highly-concurrent programming language, and yet I'm loading all of my image URLs for a given page synchronously. There are five requests, because I put five posts per page and each one has a single title image. So I made a new type to represent a list of posts, and then added a prefetch function that would spin up a separate goroutine for each post, and wait until all of them had finished, using a WaitGroup. As you can imagine, it's approximately five times faster now, as shown below.
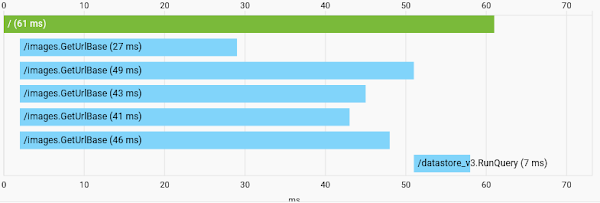
Much better.
But it turns out I had an even worse offender, the search functionality (which actually works now). A search for a common word, like "the" or "truck" or "deranged" (kidding) would load the entire corpus of posts, and all of their images serially, as shown below.
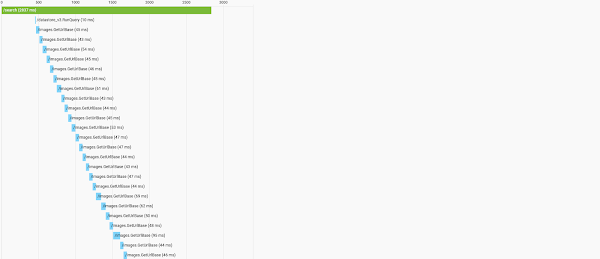
It's hard to see, but this request took nearly 3 seconds!
But running our handy-dandy new parallel prefetcher on this made quick work of that.
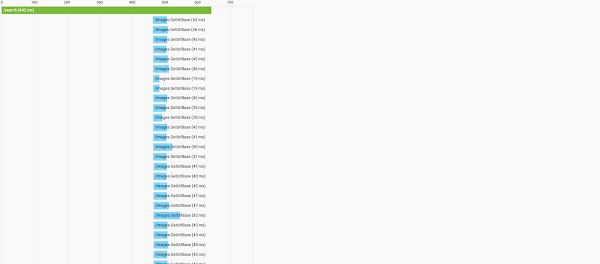
Down to 700ms.
Naturally, I'm still at the mercy of the longest-running lookup, plus building up the inverted index, which takes nearly 500 ms (and will grow linearly with the number of posts I write), but it's definitely an improvement.
New Features?
Now that I have a lean, reasonably sane codebase, what's next? I have a few ideas.
Post Comments
People have their own ideas about my ideas, and sometimes they'd like to share them in a forum visible to the rest of the Internet-connected planet. I'll definitely add these at some point, once I build up sufficient tooling and reasonable spam blocking.
Microposts
All of my posts are about the various mundane aspects of my life: whether it's leaky roofs, insurance, bicycles, or the weather, if the topic is boring and has no right being expounded about for paragraphs on end, there's a good change I'll write about it. But some of the prosaic things I want to talk about don't always warrant a whole essay, just a little blurb. What I'm describing is basically Twitter, but as an engineer with no interest in actually using Twitter, it seems reasonable to just whip up my own little system.
E-mail Subscription
For people who aren't a fan of RSS, but still want to read about my apathetic adventures.
Interactive Questions/Comments
Right now I have a comments/questions section, but it's one-way, so if people have a burning question and don't want to e-mail me or wait for me to do another Q&A, they're currently out of luck. I think it'd be cool if when you ask a question, you could get a link that would act as a private, topical chat and we could reply back and forth on that.
I have a few other features in the pipeline: I'd like to improve my search functionality, and maybe add a post listing by month or topic. I've been adding little features here and there and updating the layout, and if you have any good ideas for new features, I'm all ears.


